XAI just announced Grok
What is that?

Grok is presented as an advanced Language Model (LLM) developed over four months. It has been introduced as a successor to Grok-0, a prototype LLM with 33 billion parameters.

Grok-0's initial performance was promising, nearly matching the capabilities of the larger LLaMA 2 model on standard benchmarks while using only half the training resources.
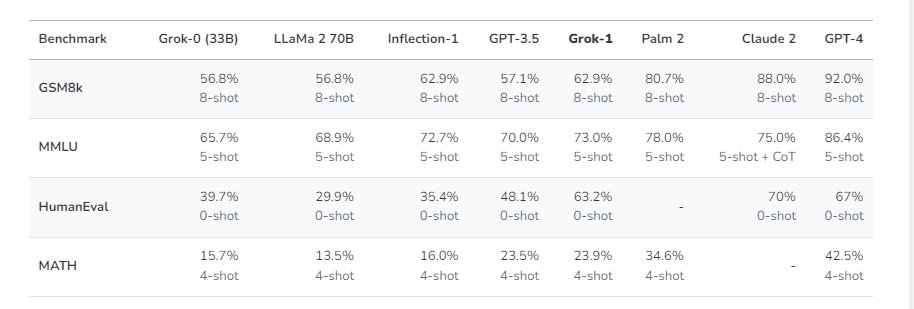
The development team claims to have significantly improved Grok's reasoning and coding abilities over two months, resulting in Grok-1. This new model is presented as state-of-the-art and has been assigned impressive scores on the HumanEval coding task and the MMLU benchmark. However, these scores are provided without context or details about the benchmark criteria, and skepticism might arise regarding the transparency and objectivity of these claims.
Additionally, Grok-1's enhanced capabilities are evaluated using various machine learning benchmarks focused on math and reasoning abilities. The choice of benchmarks and their respective relevance might warrant further scrutiny to ensure the model's claims are rigorously validated.
In summary, Grok is portrayed as an innovative LLM with substantial advancements over its predecessor.
However, skepticism may be warranted, particularly regarding the model's actual capabilities, the benchmarks used for evaluation, and the transparency of the evaluation process.
Independent, critical assessment would be essential to verify its true effectiveness and potential limitations.
These are the Benchmarks (their website):







